

日本の文字とUnicode
第8回 常用漢字・人名用漢字とUnicode
安岡孝一
- 2019.05.08
-

現代において、文字を書くということは、コンピュータやケータイのキーを打つことと、ほぼ同義になってきています。そして、現代のコンピュータにおいて文字を扱うためには、文字コード、それもUnicodeの助けを借りるしかなくなってきています。でも、Unicodeは日本語に特化して作られたわけではないので、日本の文字を扱おうとした場合、色々とヤヤコシイ点があったりします。それらのヤヤコシイ点を、できるだけ平易に説明するこのシリーズ、第8回は、常用漢字・人名用漢字と、Unicodeの関係です。
常用漢字とUnicode
日本の漢字施策のおおもとは、常用漢字表2136字です。常用漢字表は、法令、公用文書、新聞、雑誌、放送など、日本の一般の社会生活において、現代の国語を書き表す場合の漢字使用の目安です。常用漢字表2136字は、全てUnicodeに収録されています。2136字のうち、2135字が「CJK統合漢字」に、1字が「CJK統合漢字拡張B」に収録されています。どの1字が「CJK統合漢字拡張B」なのか、気になりますね。「![]() 」がU+20B9Fに収録されているのです。
」がU+20B9Fに収録されているのです。

常用漢字の「![]() 」は、U+20B9Fであって、U+53F1ではない、という点に注意が必要です。見た目は似ているのですが、常用漢字は「口へんに七」なのです。
」は、U+20B9Fであって、U+53F1ではない、という点に注意が必要です。見た目は似ているのですが、常用漢字は「口へんに七」なのです。

突き抜けるのは日本だけなんですね
Unicodeの漢字は、日本だけのものではないので、日本の常用漢字を表す際には、多少、注意しなければならない点があります。たとえば、常用漢字の「与」をU+4E0Eで表す場合を考えてみましょう。

日本の「与」と、日本以外の「与」が、U+4E0Eに統合されていますね。すなわち、日本の常用漢字の「与」をU+4E0Eで表そうとしても、多勢に無勢で「与」が表示されてしまう場合がある、ということです。では、常用漢字の「与」を、正確に表現したい場合は、どうすればいいでしょう。間違って「与」に化けたりしないよう、正確に「与」を表したい場合です。そう、IVSを使うのです。
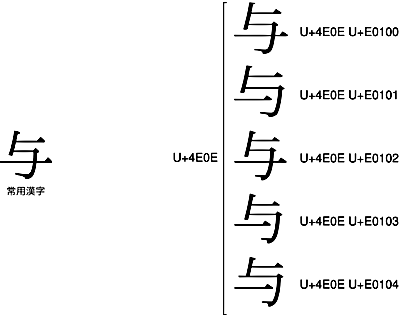
U+4E0Eには5種類のIVSが含まれていますが、これらのうち<U+4E0E U+E0100>と<U+4E0E U+E0102>が、常用漢字の「与」を表しています。第6回でもお話したとおり、IVSがダブって割り当てられてしまっているのですが、それでも、<U+4E0E U+E0100>あるいは<U+4E0E U+E0102>を使えば、常用漢字の「与」を正確に表現することができるわけです。
IVSって本当に便利です
第4回で例として挙げた「述」(U+8FF0)の常用漢字は、どうでしょう。
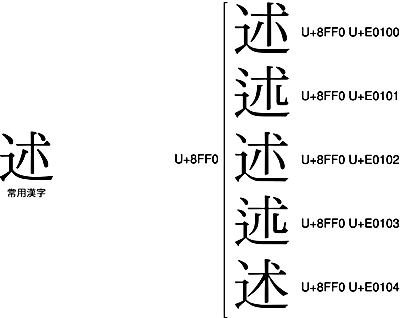
やはり、IVSがダブって割り当てられているのですが、<U+8FF0 U+E0100>あるいは<U+8FF0 U+E0102>を使えば、 常用漢字の「述」を表現できます。
細かい違いが区別されています
注意が必要なのが、常用漢字の「遡」です。
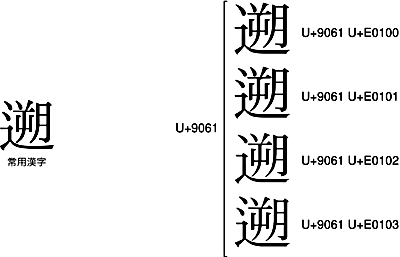
常用漢字の「遡」は、2点しんにゅうなのです。したがって、常用漢字の「遡」を表現する時には、<U+9061 U+E0101>あるいは<U+9061 U+E0103>を使わなければいけません。
そこまで分ける!? というレベルでも区別されています
微妙なのが、常用漢字の「次」です。
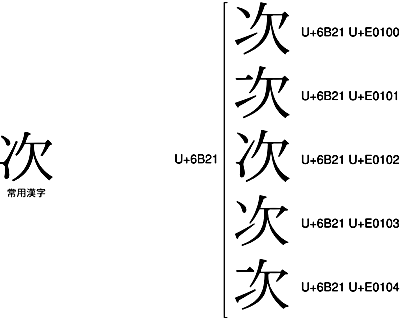
常用漢字の「次」は、にすい(冫)の下画が、かなりしっかり跳ね上がっています。したがって、<U+6B21 U+E0102>が、常用漢字の「次」に最も近い字体です。
便利だけれど完璧ではないみたいです…
では、IVSを使えば、常用漢字2136字の字体は、全て正確に表すことができるのでしょうか。実を言えば、常用漢字の「摂」は、うまく表すことができません。
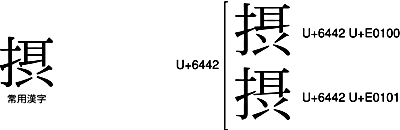
常用漢字の「摂」は、右上の「耳」の字体が、<U+6442 U+E0100>とも<U+6442 U+E0101>とも異なっています。すなわち、常用漢字の「摂」は、<U+6442 U+E0100>でも<U+6442 U+E0101>でも表現できないのです。困ったことですが、常用漢字の「摂」がIVSに追加されるのを待つしかありません。
人名用漢字とUnicode
法務省が定めている人名用漢字861字は、常用漢字2136字と合わせて、子供の名づけに使える漢字です。逆に言えば、これら2997字以外の漢字は、子供の名づけには使えません。人名用漢字861字は、全てUnicodeに収録されていますが、常用漢字と同様、正確な字体を表現したい場合には、色々な工夫が必要です。
縦ではなく横なんです
非常にヤヤコシイことになっているのが、人名用漢字の「龍」です。
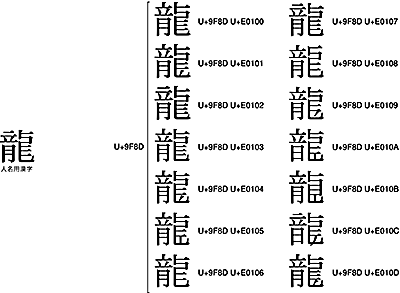
人名用漢字の「龍」の左上一画目は、実は横棒の「一」なのです。したがって、人名用漢字の「龍」をIVSで表す場合には、<U+9F8D U+E0102>か<U+9F8D U+E0107>を使うことになります。ところが、日本国内の多くの漢和辞典や、赤ちゃんの名づけ本が、人名用漢字の「龍」の一画目を、あやまって縦棒「![]() 」で掲載しているのです。この結果、<U+9F8D U+E0100>あるいは<U+9F8D U+E0103>の「龍」の方が、好んで使われてしまっているのです。Unicodeの責任ではないのですが、注意が必要でしょう。
」で掲載しているのです。この結果、<U+9F8D U+E0100>あるいは<U+9F8D U+E0103>の「龍」の方が、好んで使われてしまっているのです。Unicodeの責任ではないのですが、注意が必要でしょう。
やっぱりIVSは便利です!
「祐」と「![]() 」は、どちらも人名用漢字なのですが、U+7950に統合されています。
」は、どちらも人名用漢字なのですが、U+7950に統合されています。

人名用漢字の「祐」と「![]() 」を、それぞれ使い分けたい場合には、「祐」は<U+7950 U+E0101>か<U+7950 U+E0102>で、「
」を、それぞれ使い分けたい場合には、「祐」は<U+7950 U+E0101>か<U+7950 U+E0102>で、「![]() 」は<U+7950 U+E0100>か<U+7950 U+E0103>かU+FA4Fで、それぞれ書き分ける必要があります。
」は<U+7950 U+E0100>か<U+7950 U+E0103>かU+FA4Fで、それぞれ書き分ける必要があります。
便利だけれど人を混乱させるみたいです…
このように、同じUnicodeに統合されてしまうパターンは、常用漢字と人名用漢字の間でも起こっています。たとえば、人名用漢字の「![]() 」は、常用漢字の「謁」と同じU+8B01に統合されています。
」は、常用漢字の「謁」と同じU+8B01に統合されています。
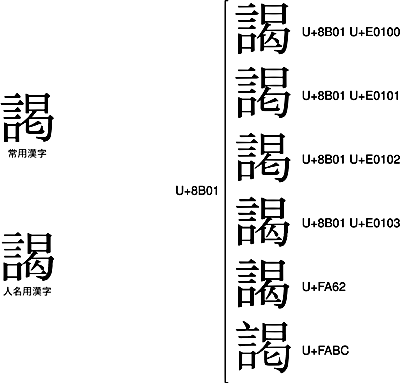
人名用漢字の「![]() 」と、常用漢字の「謁」を、それぞれ使い分けたい場合は、「
」と、常用漢字の「謁」を、それぞれ使い分けたい場合は、「![]() 」は<U+8B01 U+E0100>か<U+8B01 U+E0103>かU+FA62で、「謁」は<U+8B01 U+E0101>か<U+8B01 U+E0102>で、それぞれ書き分ける必要があります。
」は<U+8B01 U+E0100>か<U+8B01 U+E0103>かU+FA62で、「謁」は<U+8B01 U+E0101>か<U+8B01 U+E0102>で、それぞれ書き分ける必要があります。
ところが、人名用漢字の「![]() 」と、常用漢字の「掲」は、それぞれU+63EDとU+63B2という別々のUnicodeが割り当てられています。
」と、常用漢字の「掲」は、それぞれU+63EDとU+63B2という別々のUnicodeが割り当てられています。
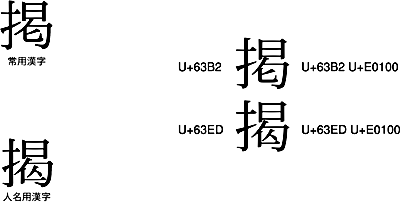
したがって、「![]() 」と「掲」に関しては、IVSを使う必要はありません。「
」と「掲」に関しては、IVSを使う必要はありません。「![]() 」はU+63ED、「掲」はU+63B2で表現すれば大丈夫です。「
」はU+63ED、「掲」はU+63B2で表現すれば大丈夫です。「![]() 」を<U+63ED U+E0100>で表してもかまいませんが、無理にそうしなくてもよい、ということです。なぜ「
」を<U+63ED U+E0100>で表してもかまいませんが、無理にそうしなくてもよい、ということです。なぜ「![]() 」と「謁」とは、扱いが違うのだろう、とは思うのですが、そういうものだとあきらめるしかありません。
」と「謁」とは、扱いが違うのだろう、とは思うのですが、そういうものだとあきらめるしかありません。
ちなみに、第6回で例として挙げたU+795Eには、常用漢字の「神」と、人名用漢字の「![]() 」が統合されています。
」が統合されています。
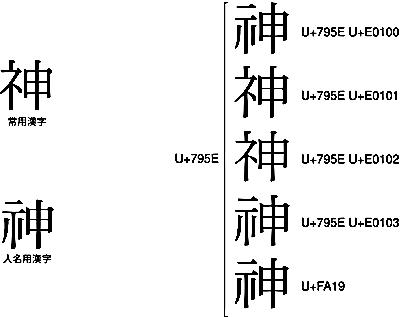
常用漢字の「神」と、人名用漢字の「![]() 」を、それぞれ使い分けたい場合は、「神」は<U+795E U+E0101>か<U+795E U+E0102>で、「
」を、それぞれ使い分けたい場合は、「神」は<U+795E U+E0101>か<U+795E U+E0102>で、「![]() 」は<U+795E U+E0100>か<U+795E U+E0103>かU+FA19で、それぞれ書き分ける必要があります。
」は<U+795E U+E0100>か<U+795E U+E0103>かU+FA19で、それぞれ書き分ける必要があります。
やっぱり非常に細かく区別されています
非常に見分けがつきにくいのが、人名用漢字の「![]() 」です。常用漢字の「逸」と同じU+9038に統合されている上に、非常によく似た字がU+284DCにも収録されているのです。
」です。常用漢字の「逸」と同じU+9038に統合されている上に、非常によく似た字がU+284DCにも収録されているのです。
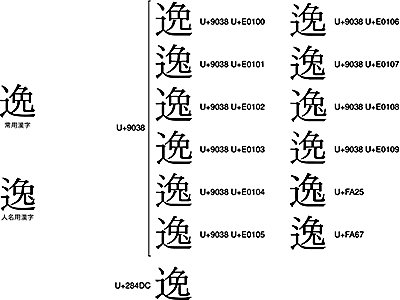
これらのうち、人名用漢字の「![]() 」として用いることができるのは、<U+9038 U+E0101>と<U+9038 U+E0107>とU+FA67です。一方、常用漢字の「逸」に使えるのは、<U+9038 U+E0100>と<U+9038 U+E0103>だけです。それ以外は、微妙に字体が異なっています。かなり注意して使う必要があるのです。
」として用いることができるのは、<U+9038 U+E0101>と<U+9038 U+E0107>とU+FA67です。一方、常用漢字の「逸」に使えるのは、<U+9038 U+E0100>と<U+9038 U+E0103>だけです。それ以外は、微妙に字体が異なっています。かなり注意して使う必要があるのです。
人名用漢字をきちんと表すならIVSで!
ここまでに見てきたように、人名用漢字861字を表現したい場合には、IVSを使う方が安全です。実際、人名用漢字861字は全てIVSに収録されており、IVSを使えば、人名用漢字の字体は、全て正確に表すことができます。
著者プロフィール

安岡 孝一 (やすおか こういち)
1965年、大阪府生まれ。
1983年、月刊『ASCII』でデビュー。
1990年、京都大学大型計算機センター助手に就任。
文字コード研究のパイオニアとして活躍し、文字コード規格JIS X 0213の制定および改正で委員を務める。
現在、京都大学人文科学研究所附属東アジア人文情報学研究センター准教授。
著書に『新しい常用漢字と人名用漢字―漢字制限の歴史―』(三省堂)、『キーボード配列 QWERTYの謎』(NTT出版)、『文字符号の歴史―欧米と日本編―』(共立出版)などがある。
http://slashdot.jp/~yasuoka/journalで、断続的に「日記」を更新中。
一覧に戻る




