

日本の文字とUnicode
第6回 続続・漢字とUnicode
安岡孝一
- 2019.05.08
-

現代において、文字を書くということは、コンピュータやケータイのキーを打つことと、ほぼ同義になってきています。そして、現代のコンピュータにおいて文字を扱うためには、文字コード、それもUnicodeの助けを借りるしかなくなってきています。でも、Unicodeは日本語に特化して作られたわけではないので、日本の文字を扱おうとした場合、色々とヤヤコシイ点があったりします。それらのヤヤコシイ点を、できるだけ平易に説明するこのシリーズ、第4回・第5回に引き続き、第6回も、漢字とUnicodeの関係です。
IVSもダブって収録
まずは「晴」(U+6674)のIVSを見てみましょう。

何だか妙な感じですね。同じ「晴」が<U+6674 U+E0100>と<U+6674 U+E0103>に、同じ「晴」が<U+6674 U+E0101>と<U+6674 U+E0102>に、それぞれダブって収録されているように見えます。実際そうなのです。<U+6674 U+E0100>と<U+6674 U+E0103>は、全く同じ「晴」をダブって収録しているのです。また、<U+6674 U+E0101>と<U+6674 U+E0102>は、全く同じ「晴」をダブって収録しているのです。どうして、こんなおかしなことになってしまっているのでしょう。
実は、<U+6674 U+E0100>と<U+6674 U+E0101>は、アメリカのAdobe社が、「晴」と「晴」を分離するために、提案したIVSです。一方、<U+6674 U+E0102>と<U+6674 U+E0103>は、日本が、「晴」と「晴」を分離するために、提案したIVSです。これらの提案は、提案元こそ違うものの、どちらも「晴」と「晴」を分離するために提案されたものですから、当然Unicodeは、これらの提案を一つにまとめるものだと思われていました。しかしUnicodeは、これらの提案をそれぞれバラバラに処理し、Adobe社からの提案には<U+6674 U+E0100>(晴)と<U+6674 U+E0101>(晴)を、日本からの提案には<U+6674 U+E0102>(晴)と<U+6674 U+E0103>(晴)を、それぞれ割り当てたのです。この結果、「晴」には<U+6674 U+E0101>と<U+6674 U+E0102>が、「晴」には<U+6674 U+E0100>と<U+6674 U+E0103>が、それぞれダブって割り当てられています。
「神」もやっぱりダブっています
「神」(U+795E)のIVSも見てみましょう。
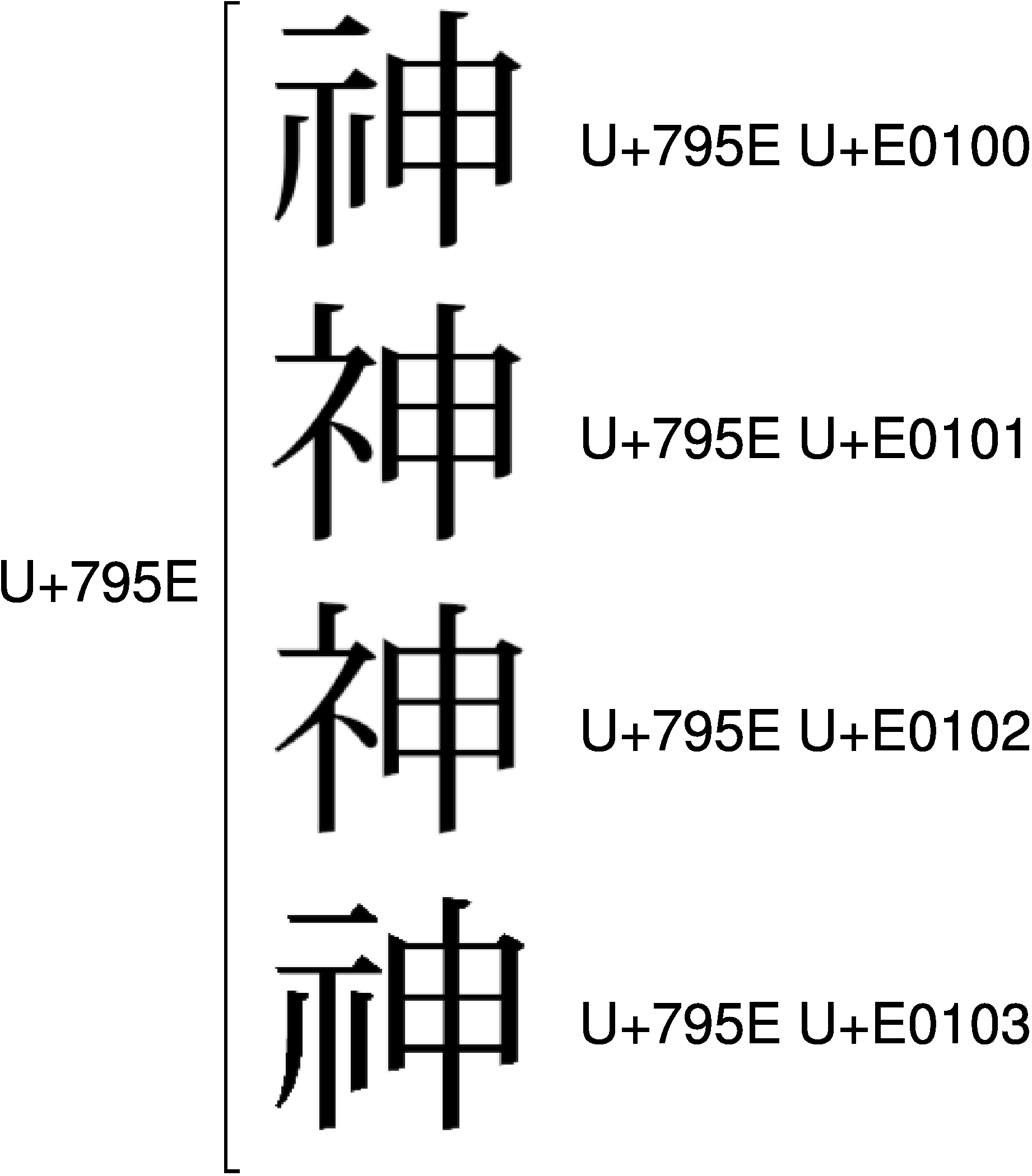
これも同じパターンです。<U+795E U+E0100>と<U+795E U+E0101>は、Adobe社が「神」と「神」を分離するために、提案したIVSです。一方、<U+795E U+E0102>と<U+795E U+E0103>は、日本が「神」と「神」を分離するために、提案したIVSです。このため、「神」には<U+795E U+E0101>と<U+795E U+E0102>が、「神」には<U+795E U+E0100>と<U+795E U+E0103>が、それぞれダブって割り当てられる結果となっています。
ダブり方がグレードアップ!
U+90F7のIVSと、U+9115のIVSは、もっとヤヤコシイ関係にあります。

Adobe社が<U+90F7 U+E0100>と<U+90F7 U+E0101>と<U+9115 U+E0100>を分離提案したのに対し、日本は<U+9115 U+E0101>~<U+9115 U+E0104>を分離提案したため、かなりヤヤコシイことになってしまいました。結論を言えば、<U+9115 U+E0100>と<U+9115 U+E0101>は同一の字体ですし、<U+90F7 U+E0101>と<U+9115 U+E0102>も同一の字体です。U+90F7のIVSだけを見ていても、あるいはU+9115のIVSだけを見ていても、両方を同時に見ない限り、<U+90F7 U+E0101>と<U+9115 U+E0102>が同一の「鄕」であることには気づかないため、かなり注意が必要な例です。
さらにグレードが上がったダブり方です!
U+5EA7のIVSと、U+2B776のIVSは、さらに凄いことになっています。
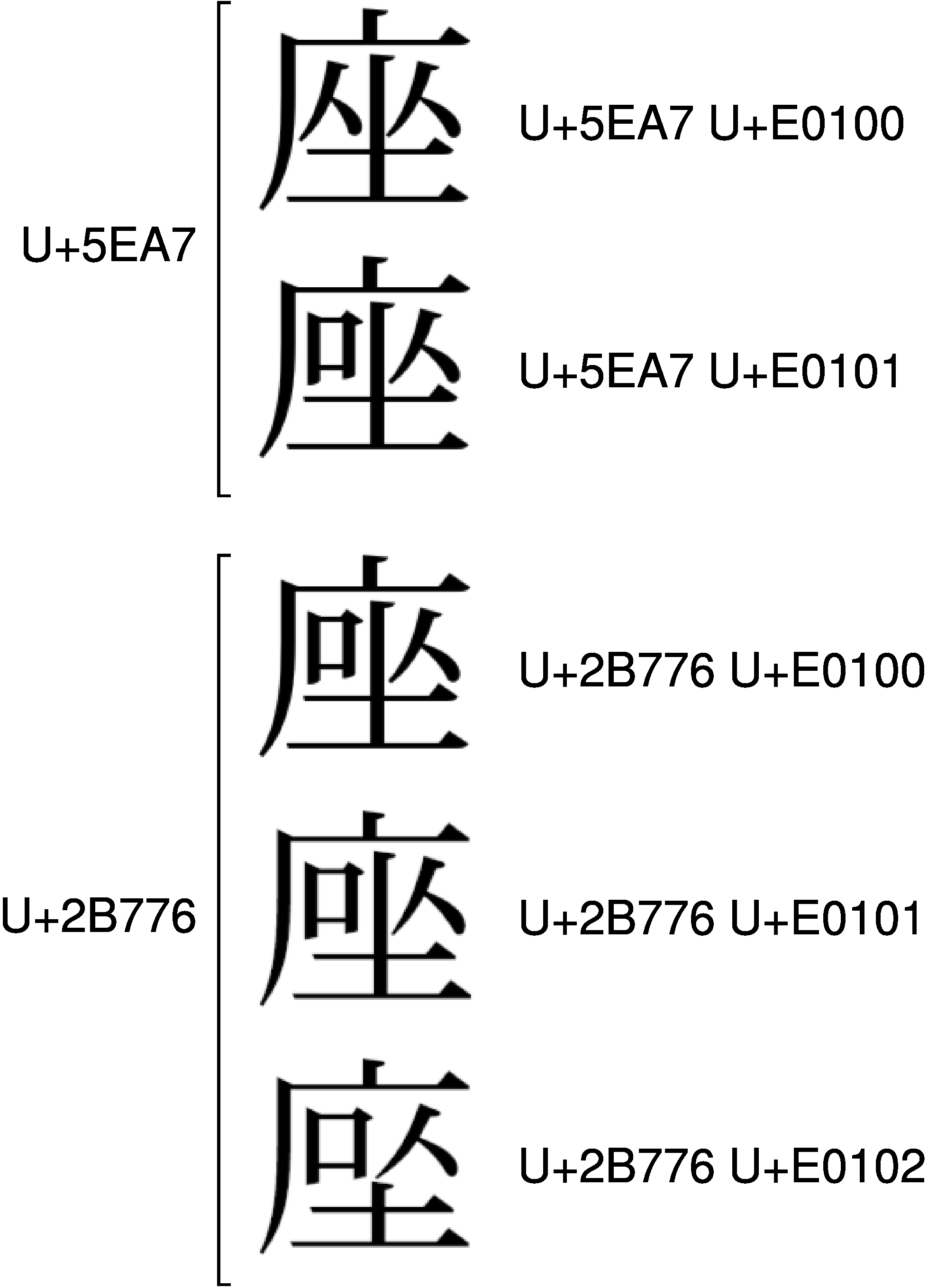
元々は、Adobe社が<U+5EA7 U+E0100>と<U+5EA7 U+E0101>を提案していました。その後U+2B776が「CJK統合漢字拡張D」(コード表参照)に追加されるに至り、Adobe社は<U+5EA7 U+E0101>と同じ字体を<U+2B776 U+E0100>に追加提案しました。一方、日本は<U+2B776 U+E0101>と<U+2B776 U+E0102>を分離提案しました。この結果、<U+5EA7 U+E0101>と<U+2B776 U+E0100>と<U+2B776 U+E0101>が同一の字体となってしまったのです。同一の字体が、3つもIVSに収録されてしまうなんて、全くもって不幸なことです。
日本のフォントとIVS
では、「鄕」を表す場合、<U+90F7 U+E0101>と<U+9115 U+E0102>のどちらのIVSを使うのが、より望ましいのでしょう。これは実は、フォントの実装次第ということになります。日本語版Windows 8 (今年10月発売予定)やMac OS X (Lion以降)は、IVSをOSレベルでサポートしているのですが、でも、これらのOSの付属フォントでIVSを実装しているものは、まだ少数です。しかも、それらのフォントも、Adobe社が提案したIVSの一部しか、現時点では実装していないようです。すなわち、それらのフォントを使う場合には、<U+90F7 U+E0101>で「鄕」を表す方が、まだ安全だということになります。
一方、フリーフォントとしては、花園明朝やIPAmj明朝が、IVSをサポートしています。これらのフォントを、日本語版Windows 8 やMac OS X (Lion以降)にインストールしましょう。花園明朝は、Adobe社が提案したIVSも、日本が提案したIVSも、全て収録しています。したがって花園明朝では、<U+90F7 U+E0101>でも<U+9115 U+E0102>でも「鄕」を表せます。一方、IPAmj明朝が収録しているのは、日本が提案したIVSの一部で、Adobe社が提案したIVSは収録していません。したがって、IPAmj明朝を使う場合には、<U+9115 U+E0102>で「鄕」を表すしかない、ということになります。使用するフォントを意識しなきゃいけないなんて、煩雑きわまりないのですが、まだまだIVSが十分に普及していないため、仕方のないところなのです。
フォントへの実装はまだまだです
では、「神」を表す場合、<U+795E U+E0100>と<U+795E U+E0103>のどちらが望ましいのでしょう。花園明朝なら<U+795E U+E0100>と<U+795E U+E0103>のどちらでも「神」を表せますが、他のフォントはどうなのでしょう。実は「神」のIVSは、フォントへの実装があまり進んでいません。たとえば、現時点のIPAmj明朝(Ver.002.01)は、<U+795E U+E0100>も<U+795E U+E0103>もどちらも収録していません。どうしてなのでしょう。
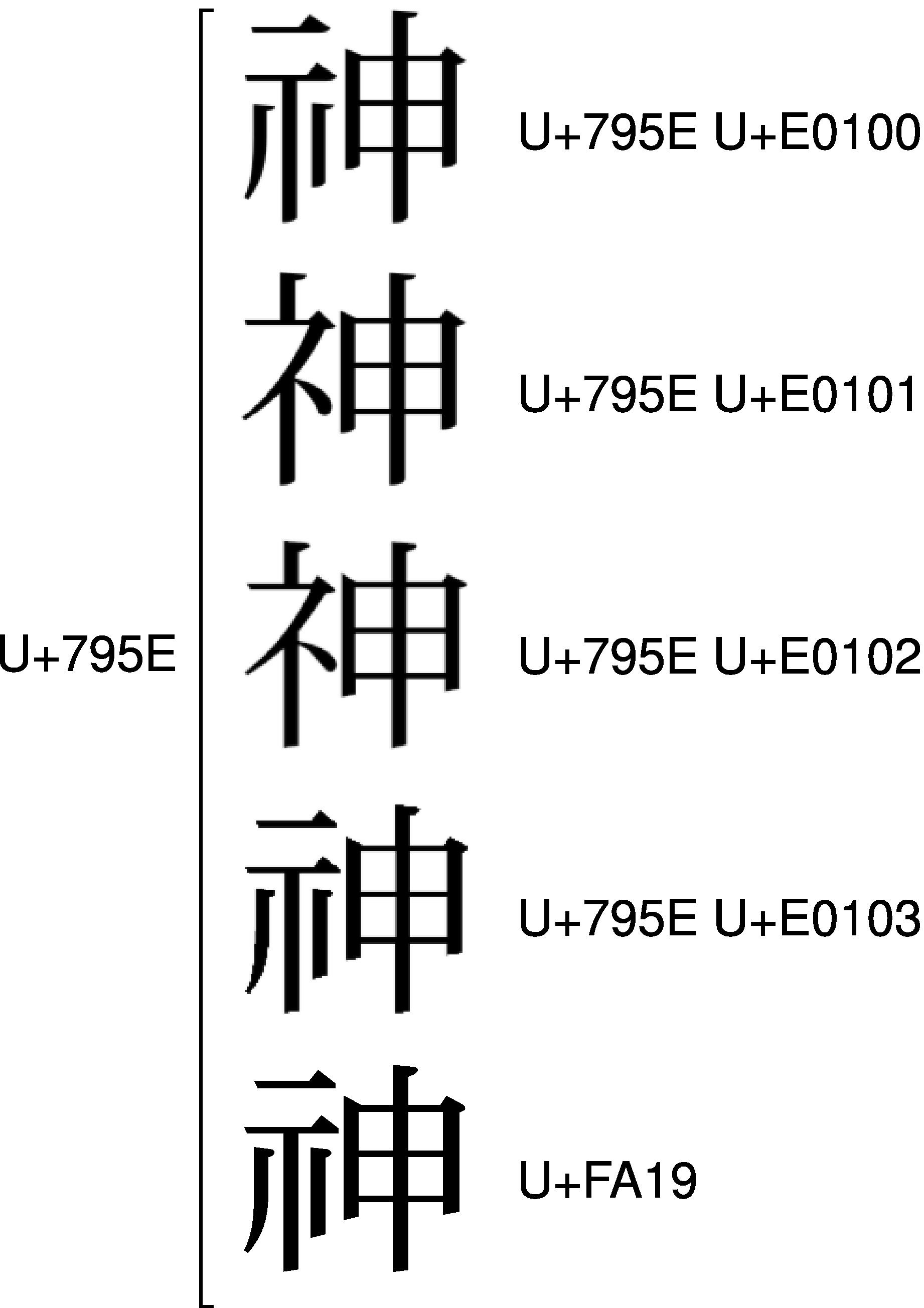
日本のフォントにおいては、「神」はU+FA19に収録されるのが一般的だからです。すなわち、「神」を表す場合、日本のフォントでは<U+795E U+E0100>でも<U+795E U+E0103>でもなく、互換漢字のU+FA19を使うのが最も一般的だ、ということなのです。UnicodeがIVSを提案する前から、日本ではU+795EとU+FA19で「神」と「神」を区別してきたのだから、日本のフォントでは「神」をU+FA19に収録するのが当然なのです。
「正規化」を気にしなくちゃいけませんよ
ただしそれは、あくまで日本固有の事情です。日本以外の人達は、そんな日本固有の事情に顧慮してはくれません。そういう海外の人達の書いたソフトウェアは、「正規化」の名の下に、テキストデータ中の互換漢字を、対応する統合漢字に、勝手に変換してしまいます。恐ろしいことです。入力データの中にU+FA19があっても、それを勝手にU+795Eに「正規化」してしまうのです。Unicodeの扱いとしては、それが許されているのです。つまり、U+FA19で「神」を表そうとしても、U+795Eの「神」に「正規化」されてしまう可能性がある、ということです。
なんで「正規化」するの? と嘆くその前に…
だったら「正規化」などしなければいい、という意見もあるでしょう。しかし、その意見はヨーロッパの人達には通じません。第2回を思い出してみましょう。たとえば「Â」は、U+00C2で表しても、<U+0041 U+0302>で表してもいいのです。でも、テキストデータの中に、U+00C2と<U+0041 U+0302>が混ざって入っていたら、データ処理がものすごく大変です。だから、全ての「Â」を、たとえば<U+0041 U+0302>に寄せてしまうのです。すなわち、テキストデータ中のU+00C2を、全て<U+0041 U+0302>に変換してしまうのです。これが「正規化」です。
あるいは、日本の濁点や半濁点も同様です。第3回を思い出してみましょう。もし、テキストデータ中に、U+304Cの「が」と、<U+304B U+3099>の「が」が、混ざって入っていたら、データ処理がものすごく大変です。だから、全ての「が」を、どちらか片方に寄せてしまうのです。これが「正規化」です。でも、その結果、U+FA19もU+795Eに寄せられてしまうのです。それが「正規化」というものです。
IVSなら将来があるかもしれません
一方、そのような「正規化」においても、<U+795E U+E0100>や<U+795E U+E0103>は、<U+795E U+E0101>や<U+795E U+E0102>とは異なるコード列として処理されます。これらのIVSは、あるいは異体字セレクタを剝ぎ取られて、U+795Eに落ちてしまう可能性はあるのですが、互換漢字のU+FA19を使うよりは、まだマシなようです。もちろん、これは可能性の問題であって、今後どうなるかは未知数なのですが、互換漢字よりIVSの方がまだ将来があるように思えます。
フォントをダブって収録しませんか?
これらの点を考えると、日本のフォント会社は、現在U+FA19に収録している「神」を、<U+795E U+E0100>と<U+795E U+E0103>の両方に、あえてダブって収録してほしい、というのが筆者の切なる願いです。別段、新しい字体を作る必要はなくて、今ある「神」を、U+FA19と<U+795E U+E0100>と<U+795E U+E0103>にダブって収録してほしいのです。それは、各フォント会社にとっても、日本語版Windows 8 やMac OS X (Lion以降)における新たなビジネス・チャンスとなるはずなのですが、いかがでしょう。
著者プロフィール

安岡 孝一 (やすおか こういち)
1965年、大阪府生まれ。
1983年、月刊『ASCII』でデビュー。
1990年、京都大学大型計算機センター助手に就任。
文字コード研究のパイオニアとして活躍し、文字コード規格JIS X 0213の制定および改正で委員を務める。
現在、京都大学人文科学研究所附属東アジア人文情報学研究センター准教授。
著書に『新しい常用漢字と人名用漢字―漢字制限の歴史―』(三省堂)、『キーボード配列 QWERTYの謎』(NTT出版)、『文字符号の歴史―欧米と日本編―』(共立出版)などがある。
http://slashdot.jp/~yasuoka/journalで、断続的に「日記」を更新中。
一覧に戻る




