

日本の文字とUnicode
第5回 続・漢字とUnicode
安岡孝一
- 2019.05.08
-

現代において、文字を書くということは、コンピュータやケータイのキーを打つことと、ほぼ同義になってきています。そして、現代のコンピュータにおいて文字を扱うためには、文字コード、それもUnicodeの助けを借りるしかなくなってきています。でも、Unicodeは日本語に特化して作られたわけではないので、日本の文字を扱おうとした場合、色々とヤヤコシイ点があったりします。それらのヤヤコシイ点を、できるだけ平易に説明するこのシリーズ、第4回に引き続き、第5回も、漢字とUnicodeの関係です。
ダブって収録された漢字
Unicodeでは、「清」と「淸」はU+6E05とU+6DF8に分離して収録されているのに、「晴」と「晴」はU+6674に統合されている、というお話を前回いたしました。でも、「晴」と「晴」を別々の文字コードで表したい、という要望は当初からあって、いくつかの方法が実際に試されてきました。カナダが提案した「互換漢字」(コード表参照)も、その一つです。

「互換漢字」のU+FA12には「晴」が収録されています。このU+FA12は、タテマエ上はU+6674と同じ文字なのですが、字体だけは「晴」にする、という不思議な文字です。その意味では、U+6674に統合されている「晴」と「晴」のうち、「晴」の方だけはU+FA12でも表すことができる、と考えてもいいでしょう。
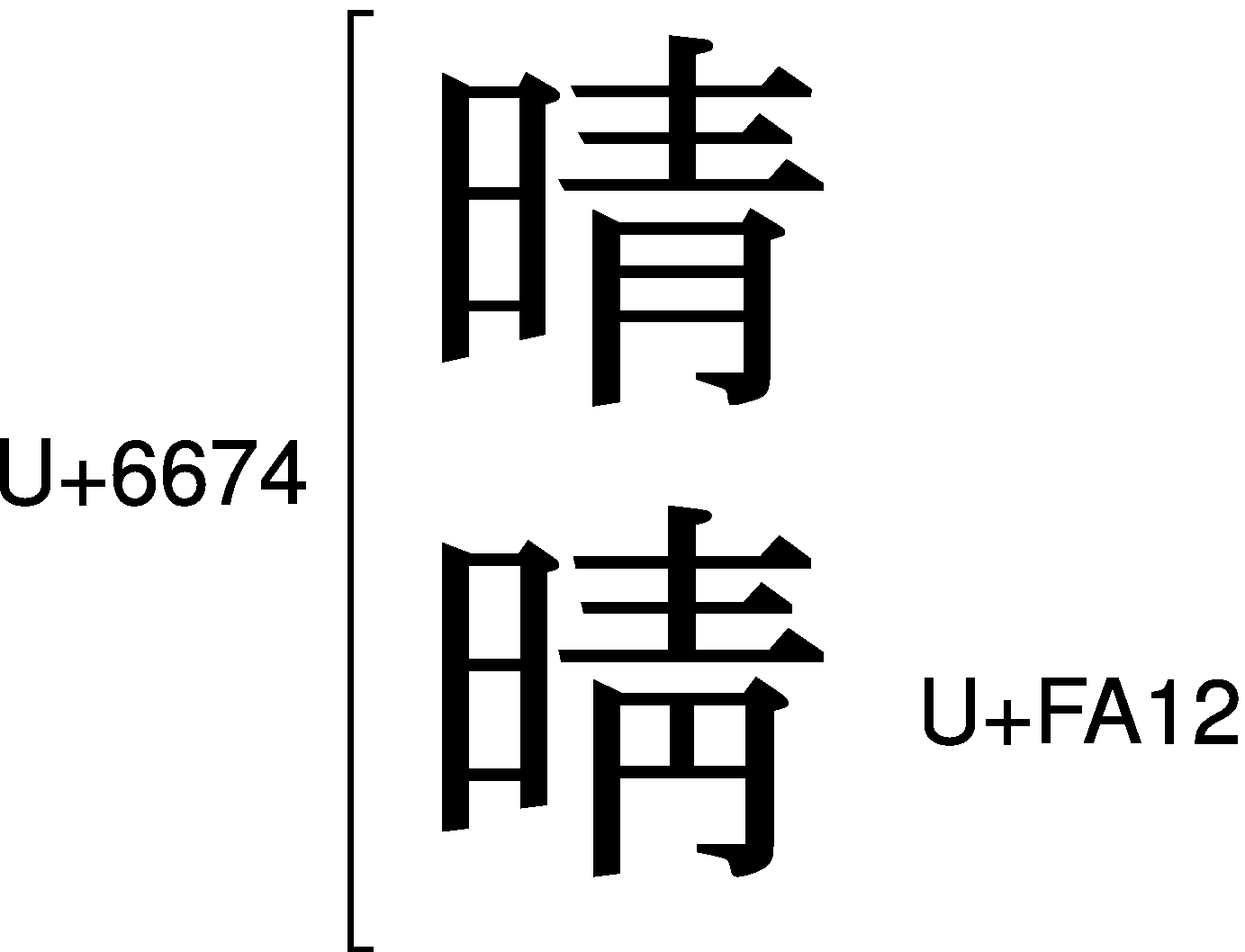
ここにおいて、U+6674とU+FA12とで「晴」と「晴」を分離できる、というのがカナダの提案趣旨でした。すなわち、カナダや日本のフォントでは、U+6674に「晴」が収録されているので、U+FA12「晴」と使い分けることができる、というのです。つまり、少なくともカナダと日本においては、U+6674「晴」とU+FA12「晴」という使い分けが可能なのです。
まあ、国ごとに事情があります
ところが、韓国や北朝鮮のフォントでは、U+6674に「晴」が収録されているので、U+6674とU+FA12は同じ「晴」になってしまいます。この問題に対し、北朝鮮の提案で、「晴」がU+FA91に追加されました。
このU+FA91も「互換漢字」の一つで、タテマエ上はU+6674と同じ文字なのですが、字体だけは「晴」にするというものです。すなわち、U+6674に統合されている「晴」と「晴」のうち、「晴」の方だけはU+FA91でも表すことができる、と考えられます。
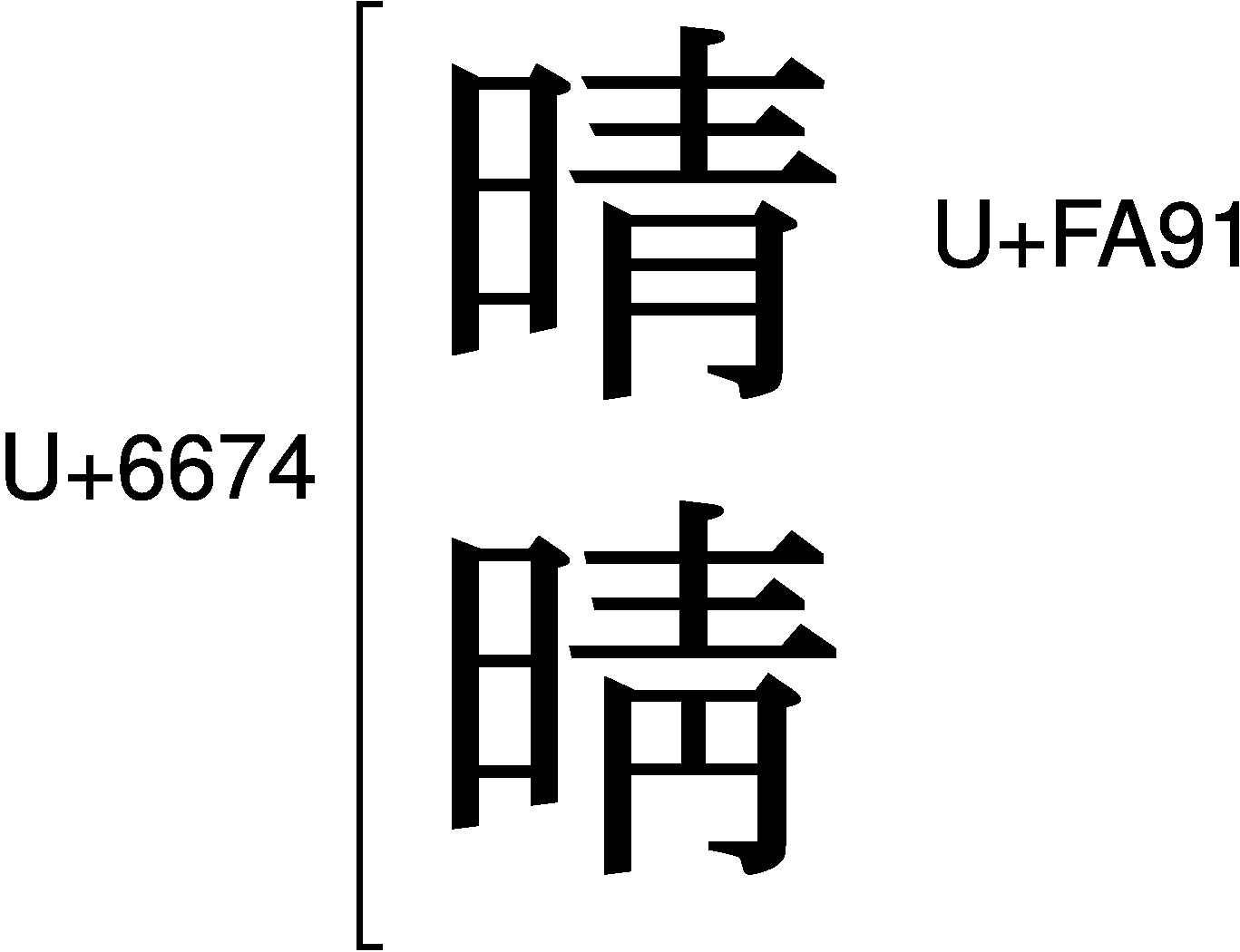
この結果、韓国や北朝鮮においては、「晴」と「晴」を、U+FA91「晴」とU+6674「晴」で使い分けることになりました。カナダや日本の使い分け(U+6674「晴」とU+FA12「晴」)とは、異なる方法になってしまっているのですが、それぞれに事情があるので仕方ありません。
八百万の神がいるから……ではないですよね
「神」と「神」の区別にも「互換漢字」が使えます。日本のフォントでは、U+795Eに「神」が収録されているので、U+FA19に「神」を追加提案したのです。

これで、少なくとも日本においては、U+795E「神」とU+FA19「神」を使い分けられるようになりました。韓国や北朝鮮のフォントでは、「神」と「神」の使い分けができないのですが、それは日本としては仕方のないところです。
「大」か「犬」かで揉めました
一方、「器」(まんなかが「大」)と「器」(まんなかが「犬」)の区別は、かなりヤヤコシイことになっています。

U+5668は「器」と「器」を統合しています。 ただ、日本においてはU+5668は「器」なので、これとは異なる「器」を、「互換漢字」のU+FA38に追加提案しました。U+FA38は、タテマエ上はU+5668と同じ文字で、字体だけは「器」というものです。ところが台湾と中国は、逆に「器」を追加提案し、それは「CJK統合漢字拡張B」(コード表参照)のU+20F96に収録されたのです。
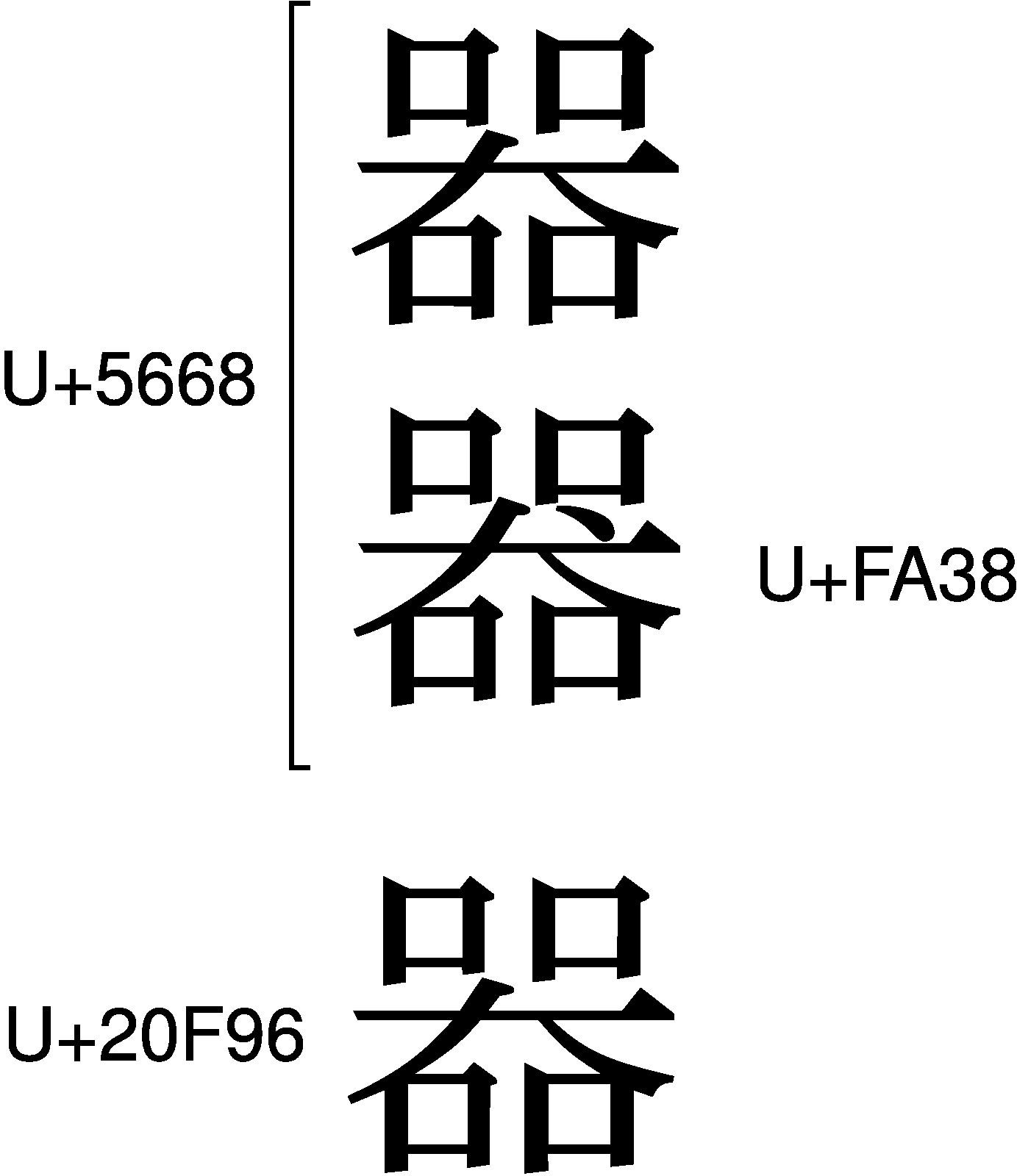
しかもU+20F96は、U+5668とは異なる別の文字、という扱いになっています。何が何だかわかりませんね。でも、日本に限っては、当初のモクロミどおり、U+5668「器」とU+FA38「器」で使い分けをおこなっています。日本の中でだけ、ちゃんと使い分けられれば、それでいいのです。
IVSで漢字を分離
けれどもUnicodeは、日本の中でだけ使い分けられればいい、という態度には首肯しませんでした。統合された漢字を、「互換漢字」の追加によって区別する方法は、国際的には限界があるし、矛盾が生じると考えたのです。そこでUnicodeが提案した新しいアイデアが、IVS (Ideographic Variation Sequence)です。
微妙な違いを区別できるんです!
IVSは、漢字を表す文字コードの直後に、U+E0100~U+E01EFの異体字セレクタを付加することで、統合された漢字を分離し、それらを区別して表すというアイデアです。例として、U+4E08のIVSを見てみましょう。
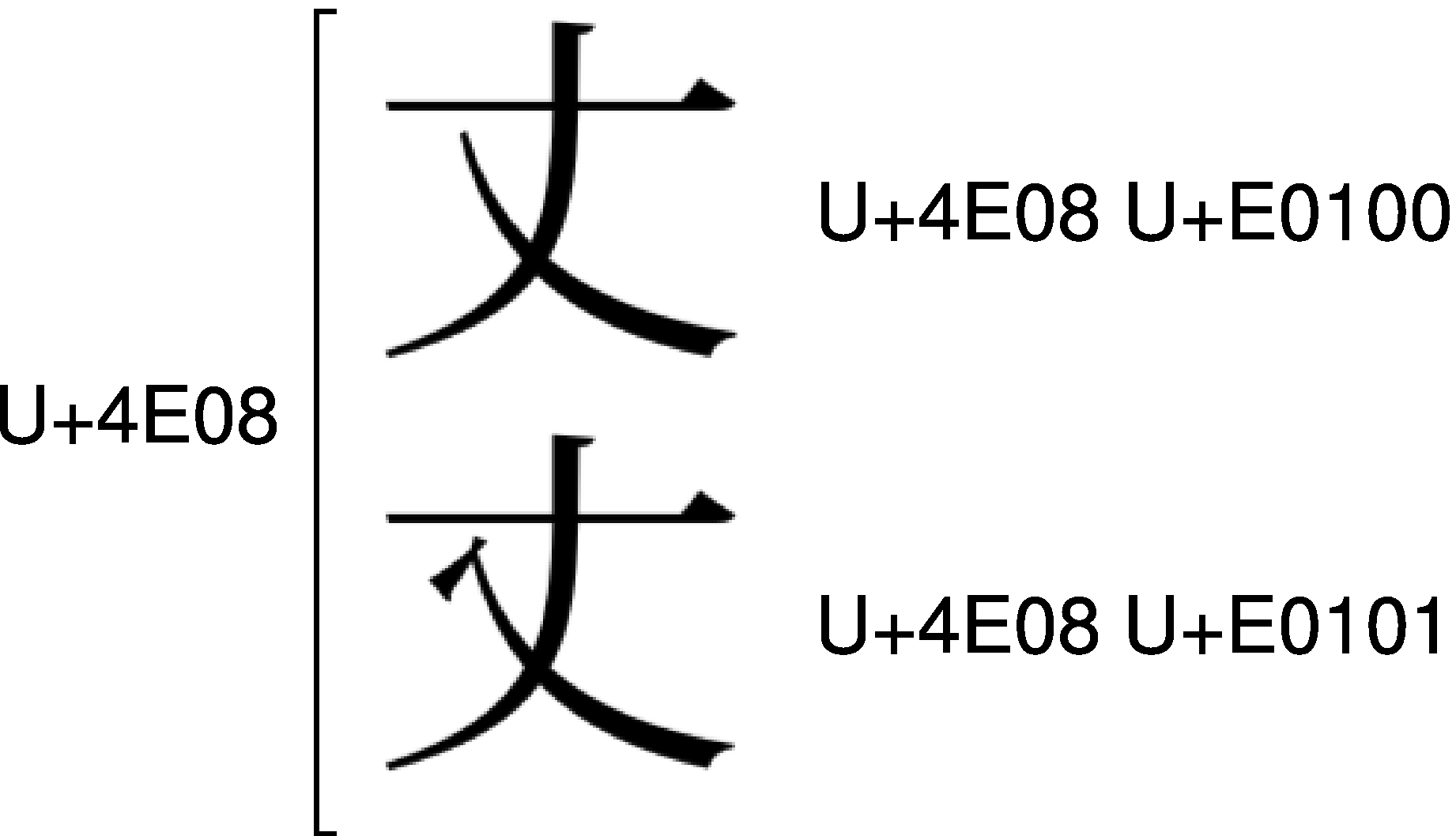
U+4E08は「丈」と「丈」を統合しています。IVSでは、これらのうち「丈」の方を<U+4E08 U+E0100>というコード列で、「丈」の方を<U+4E08 U+E0101>というコード列で、それぞれ表すのです。どちらか片方をU+4E08でゴマカすのではなく、<U+4E08 U+E0100>で「丈」を、<U+4E08 U+E0101>で「丈」を表すことにより、「丈」と「丈」を完全に分離することが可能になったのです。
次に、U+7236のIVSも見てみましょう。
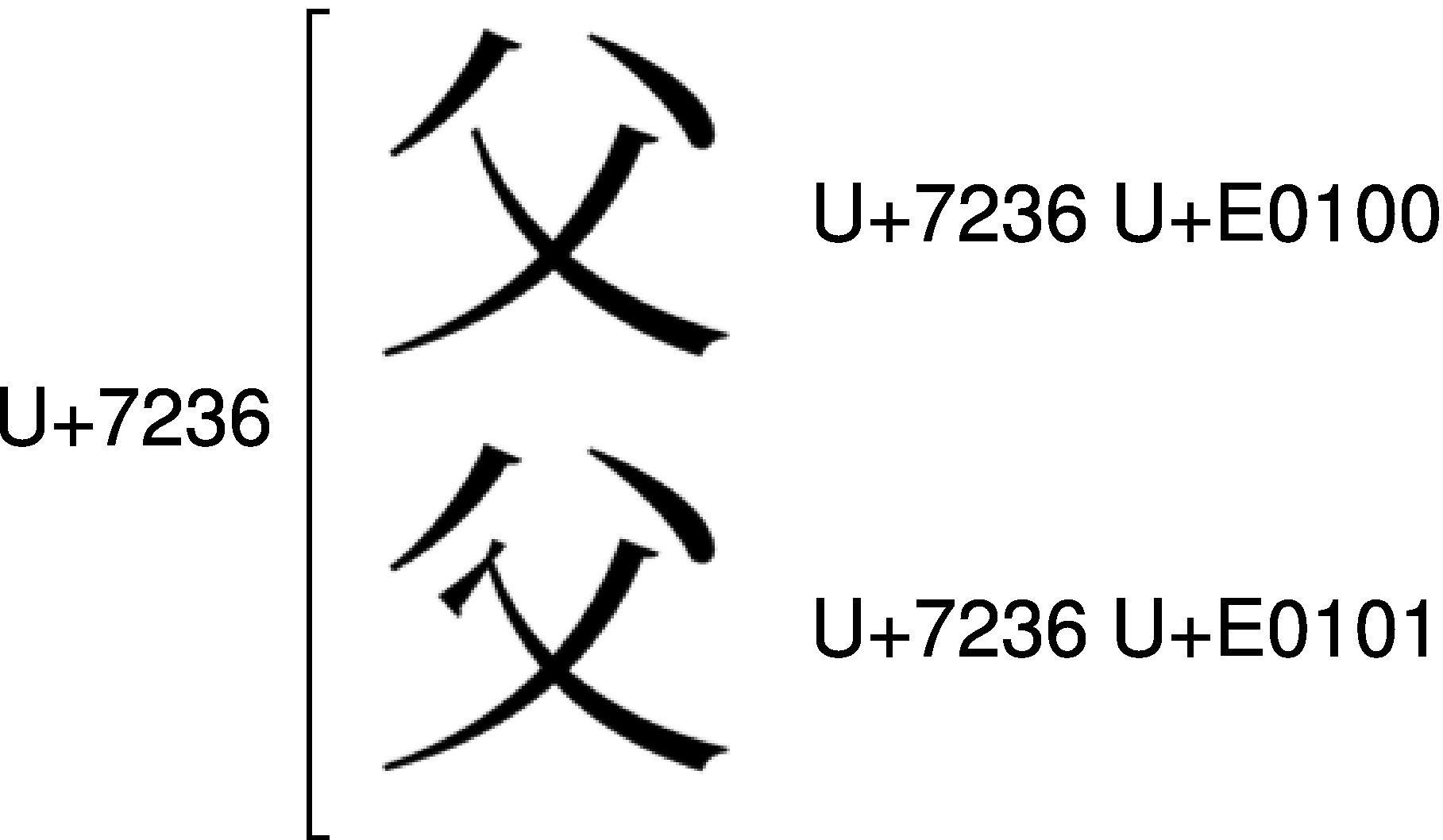
U+7236は「父」と「父」を統合しています。これをIVSでは、<U+7236 U+E0100>で「父」を、<U+7236 U+E0101>で「父」を、それぞれ表すのです。続けてU+6587のIVSも見てみましょう。
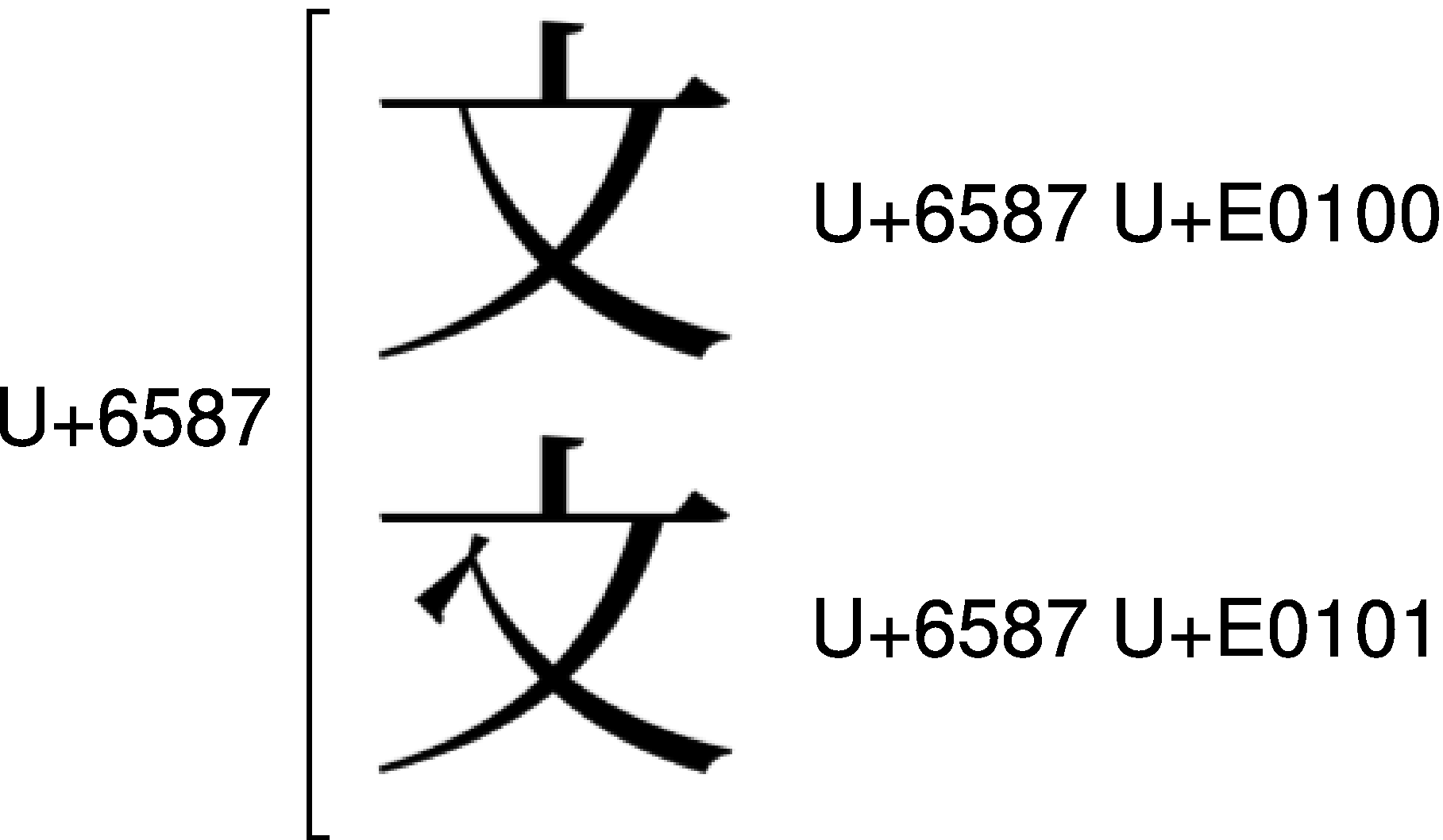
U+6587も同様に、筆押さえの無い方を<U+6587 U+E0100>で、筆押さえの有る方を<U+6587 U+E0101>で、それぞれ表すことができるのです。すなわち、「丈」や「父」や「文」の「互換漢字」をそれぞれ追加するのではなく、単に異体字セレクタを付加するだけで、筆押さえの有無を区別できる、という点がIVSの売りなのです。
いろんなニーズに対応しています
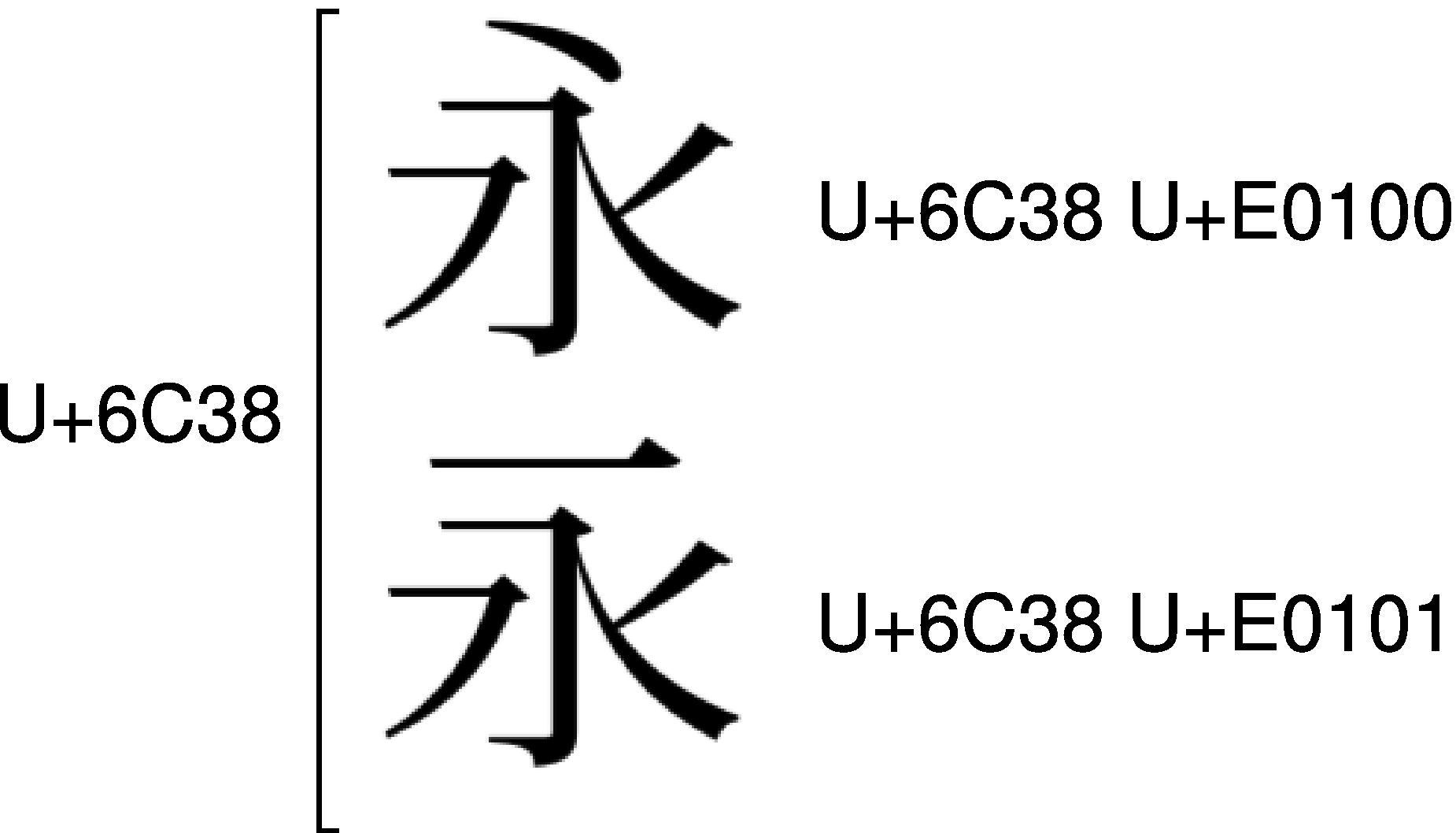
ただし、U+E0100とU+E0101は、筆押さえの違いを表しているとは限りません。U+6C38のIVSでは、<U+6C38 U+E0100>と<U+6C38 U+E0101>は、初画の「丶」と「一」の違いを表しています。
U+4E39のIVSでは、<U+4E39 U+E0100>と<U+4E39 U+E0101>は、「丶」と「丨」の違いを表しています。

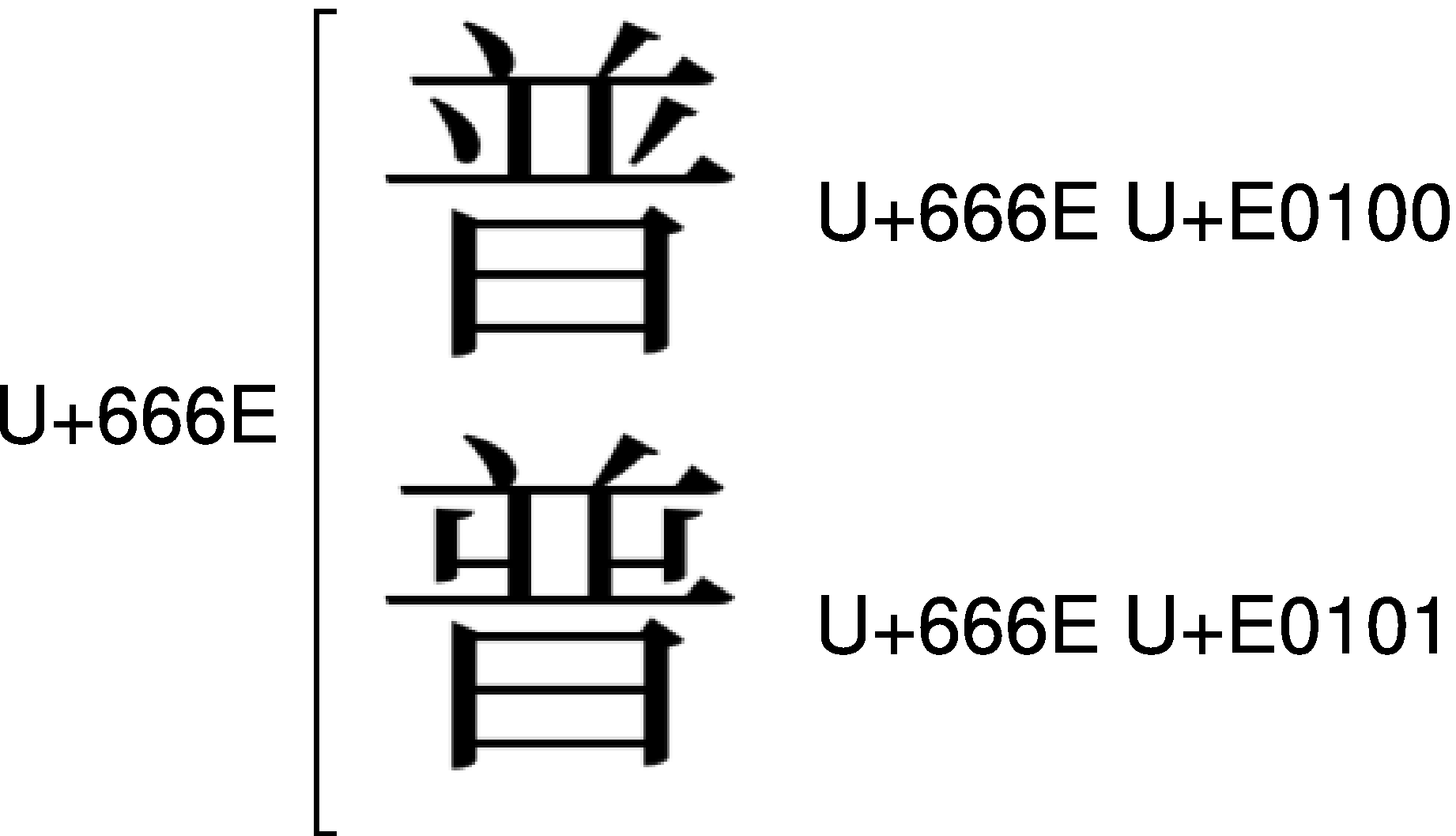
U+666EのIVSでは、<U+666E U+E0100>と<U+666E U+E0101>とで、かなり字体が異なっています。
U+60B2のIVSでは、<U+60B2 U+E0100>と<U+60B2 U+E0101>とで、 左下画が突き抜けるかどうかの違いがあります。

でもU+975EのIVSには、<U+975E U+E0100>だけしか登録されておらず、左下画が突き抜けない「非」は、現時点のIVSでは表現できません。

それぞれの漢字によって、U+E0100やU+E0101の意味は変わるのです。異体字セレクタは、単純に異体字を分離するだけのもので、その意味は漢字ごとに異なっているのです。
異体字セレクタは、U+E0100~U+E01EFの240種類が準備されています(コード表参照)。したがって、最大240種類の異体字が、IVSで表現できます。たとえばU+6982では、4種類のIVSが、それぞれ微妙に異なる字体を表しています。

ワタナベさんには気を遣います……
では、現時点で最も種類の多いIVSは、どの漢字に対するものでしょう。 すごく気になりますね。答はU+9089「邉」です。U+9089には、31種類のIVSが含まれています。

しかし、IVSによる漢字の分離は、U+6674「晴」やU+795E「神」に関しては、必ずしもうまくいきませんでした。次回は、それをお話しすることにいたしましょう。
著者プロフィール

安岡 孝一 (やすおか こういち)
1965年、大阪府生まれ。
1983年、月刊『ASCII』でデビュー。
1990年、京都大学大型計算機センター助手に就任。
文字コード研究のパイオニアとして活躍し、文字コード規格JIS X 0213の制定および改正で委員を務める。
現在、京都大学人文科学研究所附属東アジア人文情報学研究センター准教授。
著書に『新しい常用漢字と人名用漢字―漢字制限の歴史―』(三省堂)、『キーボード配列 QWERTYの謎』(NTT出版)、『文字符号の歴史―欧米と日本編―』(共立出版)などがある。
http://slashdot.jp/~yasuoka/journalで、断続的に「日記」を更新中。
一覧に戻る




