

日本の文字とUnicode
第4回 漢字とUnicode
安岡孝一
- 2019.05.08
-

現代において、文字を書くということは、コンピュータやケータイのキーを打つことと、ほぼ同義になってきています。そして、現代のコンピュータにおいて文字を扱うためには、文字コード、それもUnicodeの助けを借りるしかなくなってきています。でも、Unicodeは日本語に特化して作られたわけではないので、日本の文字を扱おうとした場合、色々とヤヤコシイ点があったりします。それらのヤヤコシイ点を、できるだけ平易に説明するこのシリーズ、第4回は、漢字とUnicodeの関係です。
漢字を大量に収録
Unicodeには、漢字が大量に収録されています。 ざっくり言えば、Unicodeに収録されている文字のうち、 およそ3分の2にあたる70,000字強が、漢字なのです。
最初はU+4E00~U+9FFF(コード表参照)に、約20,000字の「CJK統合漢字」が収録されているだけでした。 次にU+3400~U+4DBF(コード表参照)に、6,500字強の「CJK統合漢字拡張A」が追加されました。 さらにU+20000~U+2A6DF(コード表参照)に、約42,000字の「CJK統合漢字拡張B」が追加されました。 その後も追加は続き、U+2A700~U+2B73F(コード表参照)に「CJK統合漢字拡張C」が、 続くU+2B740~U+2B81F(コード表参照)に「CJK統合漢字拡張D」が、 それぞれ追加されています。 Unicodeへの漢字追加は、とどまるところを知りません。
しかも、これらの「CJK統合漢字」や「CJK統合漢字拡張A~D」とは別に、U+F900~U+FAFF(コード表参照)とU+2F800~U+2FA1F(コード表参照)に「互換漢字」が収録されています。 でも今は「互換漢字」の話は後回しにして、 まずは「CJK統合漢字」を見ていくことにしましょう。 そもそも「CJK統合漢字」の「CJK」って何なんでしょう?
CJKは頭文字
CはChina、JはJapan、KはKoreaの頭文字で、 中国と日本と韓国を意味しています。 「CJK統合漢字」とは、すなわち、中国と日本と韓国の漢字を統合したもの、 ぐらいの意味だと考えればいいでしょう。 ただし、Cには台湾と香港が含まれますし、Kには北朝鮮が含まれますし、 さらには、ベトナムも途中から参加したりしています。 「漢字文化圏」の漢字をとにかく全部統合したもの、 というのが、Unicodeが収録すべき漢字の最終目標なのです。 ちなみに、ベトナムは古文書にだけ漢字が必要で、 現代では全くと言っていいほど漢字を使わないのですが、 「CJK」にベトナムを含める場合には「CJKV」と呼ぶこともあります。
漢字統合とは何か
「CJK統合漢字」の最初の部分を見てみましょう。 「4E00」のところに「一」が6つも並んでいます。
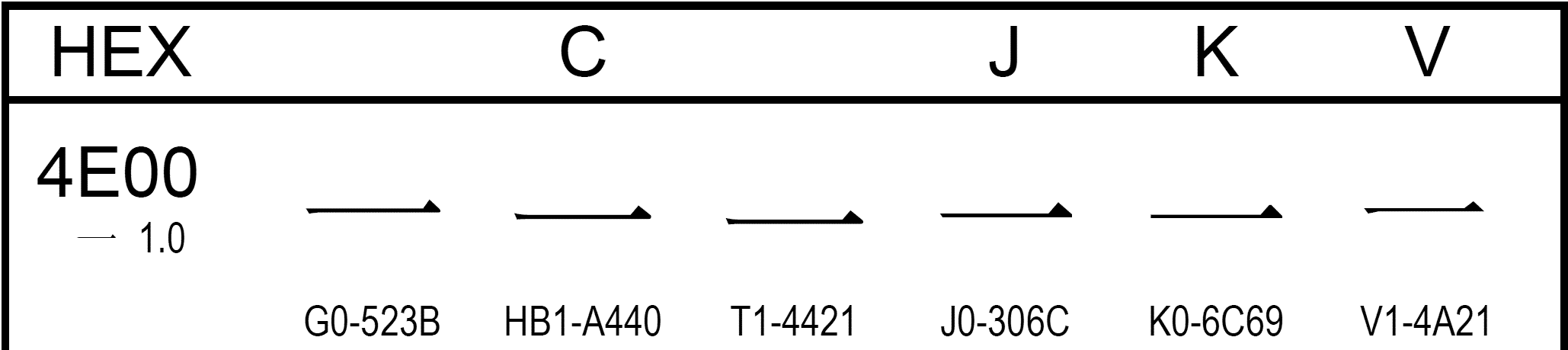
Unicodeの漢字は、中国・香港・台湾・日本・韓国・ベトナムの、 文字コード国内規格や各国提案を統合して作られたものです。 出所を示すため、それぞれの漢字の下に原規格符号が記されています。 原規格符号の頭文字は、中国がG、香港がH、台湾がT、 日本がJ、韓国がK、ベトナムがV、(シンガポールがGS、北朝鮮がKP、マカオがM、 アメリカとカナダがU)となっています。 U+4E00には、中国の「一」も、香港の「一」も、台湾の「一」も、 日本の「一」も、韓国の「一」も、ベトナムの「一」も、 発音等にかかわらず、統合して収録されているのです。 すなわち、漢字の「一」に対しては、国や地域を問わずU+4E00を用いる、 というのが、漢字統合の基本的な考え方なのです。
何だかピンと来ませんね。U+795Eの「神」も見てみましょう。

日本の「神」と、韓国の「神」は、 明らかに字体が違います。 中国・香港・台湾の「神」も、 日本の「神」に似ているものの、一画目が異なります。 右端にあるベトナムの字体も、また微妙に違いますね。 U+795Eは、これらの異なる字体を、全て統合して収録しているのです。 逆の言い方をすれば、U+795Eは、 「神」と「神」を区別することができないのです。 礻へんの「神」だろうが、 示へんの「神」だろうが、 とにかくU+795Eで表されるのです。 Unicodeは基本的に、礻へんと示へんを統合しており、 これらを区別しないのです。
統合=字体を区別しない、ということ?
では、草かんむりの漢字はどうでしょう。U+82B1の「花」を見てみましょう。

中国・日本・ベトナムでは、3画の草かんむりが使われています。 一方、香港・台湾・韓国の草かんむりは、4画です。 しかしUnicodeは、これらを統合していて、区別しません。 全て、U+82B1で表されるのです。
Unicodeは、しんにゅう「辶」の形や点の数も、全く気にしません。 U+8FF0の「述」を見てみましょう。

香港と台湾がグネグネとしたしんにゅうで、 中国と日本が1点しんにゅう、 韓国とベトナムが2点しんにゅうです。 しかも、しんにゅう以外の部分もかなりバラバラなのですが、 これらが全てU+8FF0に統合されているのです。
こんなに違っても統合されちゃいます!
日本の「写」と、 中国の「写」は、 字体がかなり異なっているのですが、同じU+5199に統合されています。 「写」の最終画が、突き抜けていようが突き抜けていまいが、お構いなしです。

日本の「写」と、 中国の「写」は、 どちらも「寫」を簡単にした字ですから、 これらを統合してもかまわない、という考え方も理解できなくはありません。 しかし、そうは言っても、 「写」と「写」の字体差は、 どうにも気になるところです。
意味は気にしません!
しかも、日本と中国で同じ意味かどうか、という点は、 漢字統合においては、必ずしも考慮されているわけではありません。 たとえば、 日本の「机」と、 中国の「机」は、 同じU+673Aに統合されています。

日本の「机」は「つくえ」を意味するのですが、 でも、 現代中国の「机」は「機」を簡単にした字なのです。 すなわち、日本の「机」と 中国の「机」は、 現代においては、意味の異なる全く別の漢字なのです。 しかしUnicodeは、漢字に限っては意味に踏み込まず、 形の似た漢字であれば統合する、という方針を取っているのです。
あれ? 区別したりしなかったり……
ではUnicodeが、形の似た漢字を全て統合しているかというと、 これがそうでもないのです。 たとえば「靑」と「青」には、 それぞれU+9751とU+9752という別々のコードが割り振られています。
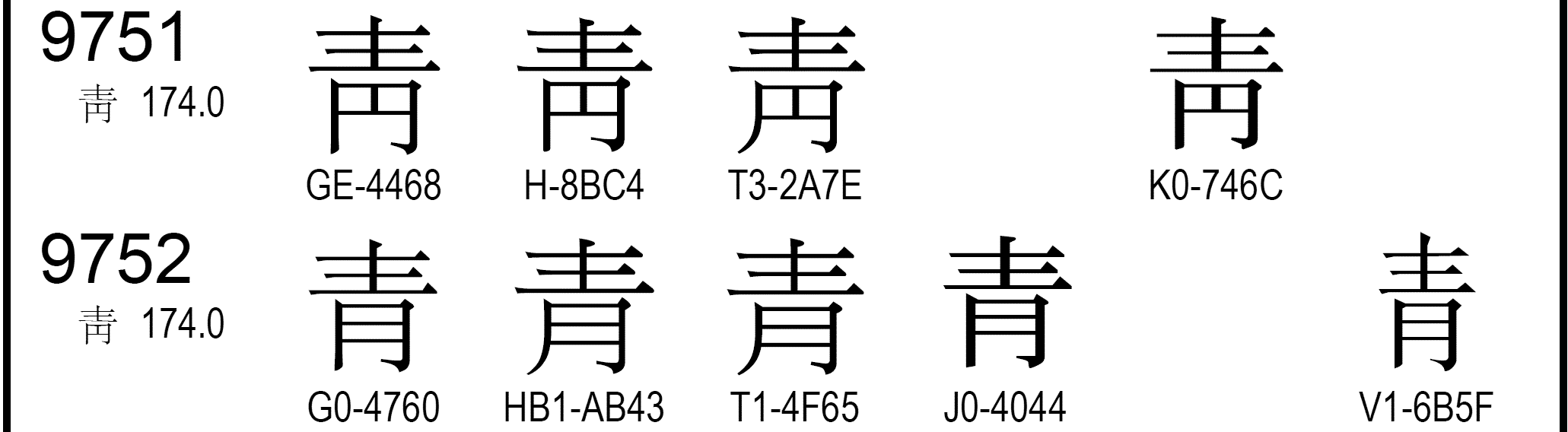
同じように「淸」と「清」には、 それぞれU+6DF8とU+6E05という別々のコードが割り振られています。

ところが「晴」と「晴」は、U+6674に統合されています。

変ですよね。 「淸」と「清」がU+6DF8とU+6E05で区別されているのに、 「晴」と「晴」はU+6674に統合されているのです。 「清」を書く場合には、U+6E05を使えば、 「淸」に化けたりすることはありません。 ところが「晴」を書く場合には、U+6674を使ったところで、 「晴」に化けてしまう可能性があるのです。
漢字統合にルールはあるの?
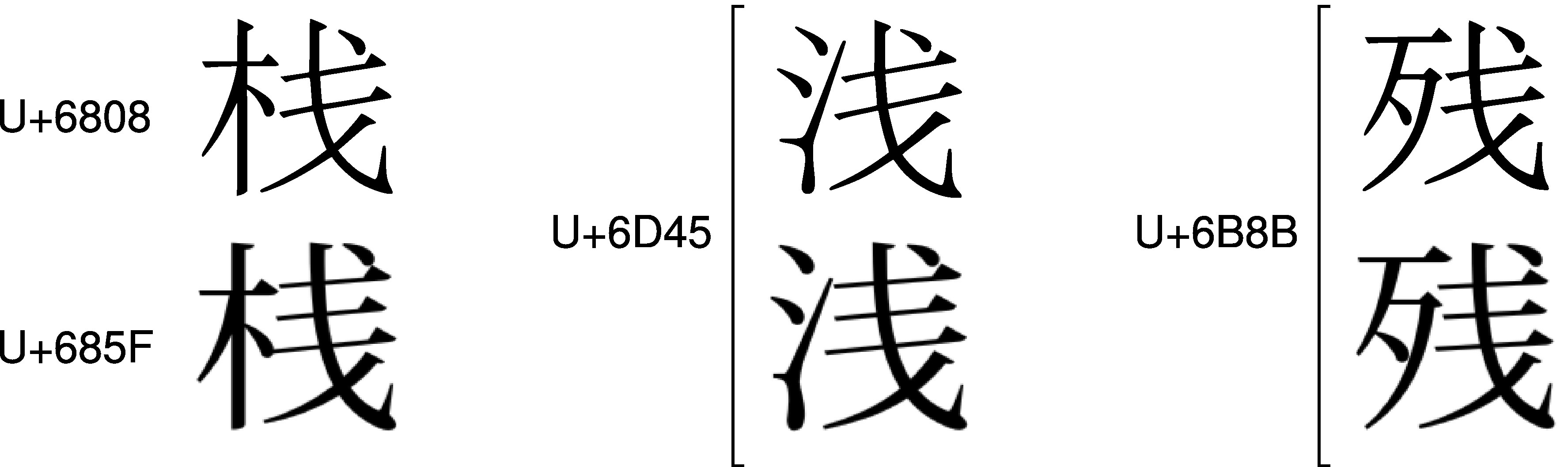
Unicodeでは、こういう妙な漢字統合の例は、枚挙にいとまがありません。 たとえば、 中国の「栈」にはU+6808、 日本の「桟」にはU+685F、という別々のコードが割り振られていて、 「栈」と「桟」は区別されています。 ところが、 中国の「浅」にはU+6D45、 日本の「浅」にもU+6D45、という同じコードが割り振られていて、 結果的に「浅」と「浅」は統合されてしまっているのです。 また、 中国の「残」と日本の「残」も、U+6B8Bに統合されています。
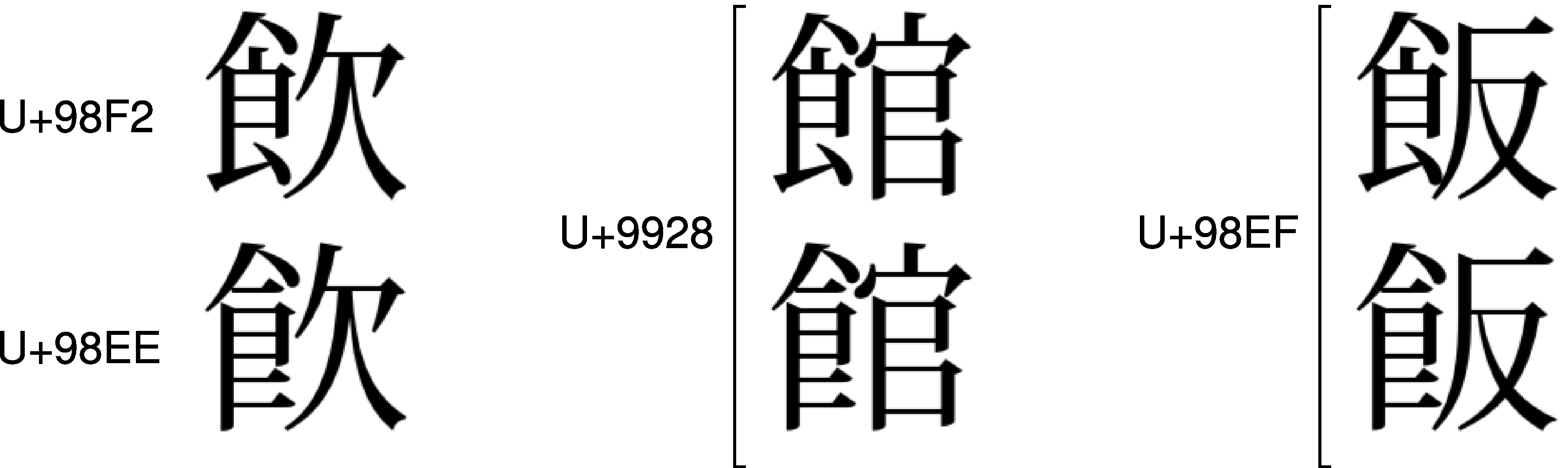
あるいは、「飲」にはU+98F2、 「飮」にはU+98EE、という別々のコードが割り振られていて、 「飲」と「飮」は区別されています。 ところが、 「館」にはU+9928、 「館」にもU+9928、という同じコードが割り振られていて、 「館」と「館」は統合されてしまっています。 また、「飯」と「飯」も、U+98EFに統合されています。
ルールはない! ってことですか……
すなわち、どの漢字とどの漢字を統合し、どの漢字とどの漢字を区別するか、 という点において、Unicodeには明確なルールがない、ということです。 あるいは、当初はルールがあったのですが、 作業途中でのルール変更や、作業ミスによって、 もはやルールがわからなくなってしまった、ということかもしれません。 どちらにしろ、ある漢字とある漢字が、同じコードに統合されるか、 別のコードに分離されるか、という点については、 コード表全体を見渡してみないとわからないのが現状なのです。
では、U+6674に統合されている「晴」と「晴」とを、 どうしても使い分けたい人は、どうすればいいのでしょう。 次回は、それをお話しすることにいたしましょう。
著者プロフィール

安岡 孝一 (やすおか こういち)
1965年、大阪府生まれ。
1983年、月刊『ASCII』でデビュー。
1990年、京都大学大型計算機センター助手に就任。
文字コード研究のパイオニアとして活躍し、文字コード規格JIS X 0213の制定および改正で委員を務める。
現在、京都大学人文科学研究所附属東アジア人文情報学研究センター准教授。
著書に『新しい常用漢字と人名用漢字―漢字制限の歴史―』(三省堂)、『キーボード配列 QWERTYの謎』(NTT出版)、『文字符号の歴史―欧米と日本編―』(共立出版)などがある。
http://slashdot.jp/~yasuoka/journalで、断続的に「日記」を更新中。
一覧に戻る




